
Protokół IP
Protokół IP (ang. Internet Protocol) implementuje warstwę sieci. Jest to protokół bezpołączeniowy. Użycie protokołu IP pozwala na przesyłanie datagramów bez zapewnienia niezawodności. Protokół ten zapewnia segmentację datagramów celem przesyłania ich przez łącza o różnej maksymalnej długości pakietu.
Struktura datagramu IP
Strukturę nagłówka protokołu IP przedstawia rysunek 2.2. Przedstawione na nim pola mają następujące znaczenie:
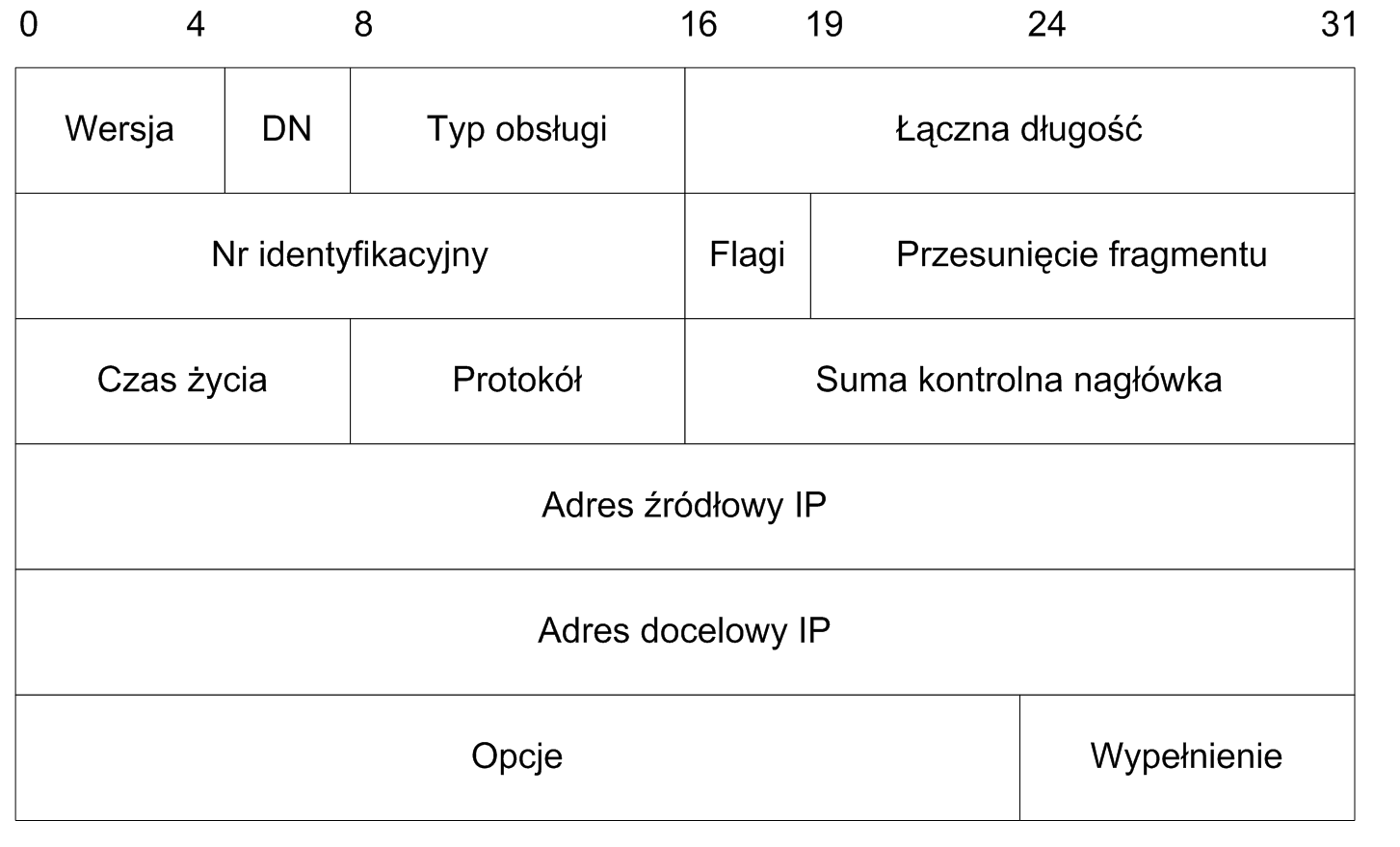
Rys. 2.2. Nagłówek datagramu protokołu IP
- Wersja – numer wersji protokołu; obecnie powszechnie stosowana jest wersja 4,
DN – długość przedstawionego tu nagłówka w słowach 32-bitowych,
Typ obsługi – informacja o wymaganiach na jakość obsługi datagramu; zawiera poziom ważności pakietu oraz może zawierać wymagania:
minimalizacji opóźnienia,
maksymalizacji przepustowości,
maksymalizacji niezawodności,
minimalizacji kosztu;
wymagania określone w polu typu obsługi są zazwyczaj ignorowane,
Łączna długość – długość całego datagramu (nagłówka i danych razem) w bajtach,
Nr identyfikacyjny – numer nadawany pakietom w celu poprawnego złożenia ich po fragmentacji; każdy fragment danego pakietu ma ten sam numer identyfikacyjny,
Flagi – znaczniki bitowe, mogące oznaczać, że danego datagramu nie należy fragmentować lub że jest to ostatni fragment,
Przesunięcie fragmentu – w przypadku fragmentacji podaje położenie danego fragmentu względem początku pakietu przed fragmentacją w 64-bitowych jednostkach; w przypadku braku fragmentacji równe zeru,
Czas życia (ang. Time To Live, TTL) – licznik, który jest zmniejszany o 1 za każdym przejściem datagramu przez router, a gdy osiągnie zero, datagram jest usuwany; ma na celu zapobieganie niekończącemu się przesyłaniu datagramów, które uległy zapętleniu; licznik powinien być tak ustawiony, aby przy prawidłowej pracy sieci nie zdążył osiągnąć zera przed dostarczeniem datagramu do celu,
Protokół – kod oznaczający protokół wyższej warstwy, którego dane zawarte są w polu danych tego datagramu; mogą być to protokoły TCP, UDP, ICMP i inne,
Suma kontrolna nagłówka – potwierdza nienaruszenie danych zawartych w omawianym tu nagłówku; gdy nie odpowiada zawartości nagłówka, datagram jest w całości odrzucany,
Adres źródłowy IP – 32-bitowy adres węzła nadającego dany datagram, w formacie omówionym w podrozdziale 2.1.2,
Adres docelowy IP – adres węzła, do którego skierowany jest dany datagram,
Opcje – pole o zmiennej długości, mogące zawierać opcje dotyczące sposobu wyznaczania trasy, bezpieczeństwa, znakowania czasu przybycia datagramu do routerów i inne,
Wypełnienie – dopełnia długość nagłówka do najbliższej wielokrotności 32 bitów; wielkość tego pola zależy od wielkości pola opcji.
Po nagłówku IP następują dane, zawierające informacje protokołu wyższej warstwy.
Adresowanie w protokole IP
Adresy stosowane w protokole IP mają długość 32 bitów. Dla ułatwienia zapisu przyjęto, że adres ten dzieli się na 4 grupy po 8 bitów, które są zapisywane w postaci liczb w systemie dziesiętnym, oddzielonych kropkami. Każda z tych liczb mieści się w zakresie od 0 do 255. Przykładowy adres IP w tym zapisie to 195.34.101.29. Adres IP jednoznacznie identyfikuje urządzenie w sieci Internet.
K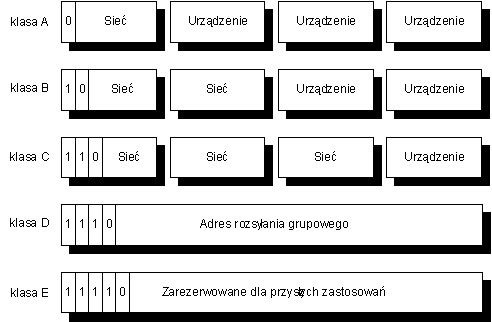
ażdy adres IP składa się z dwóch zasadniczych części: adresu sieci i numeru urządzenia w obrębie sieci. Sposób podziału na te części nie jest stały. W związku z tym wyróżnia się pięć klas adresów IP, różniących się wielkością pól adresu sieci i numeru urządzenia. Adresy należące do tych klas przedstawiono schematycznie na rysunku 2.3. Klasę adresu rozpoznaje się po jego najstarszych bitach.
J
Rys. 2.3. Diagram przedstawiający strukturę adresu IP w grupach A-E
ak widać, adresy klasy A przewidziane są dla sieci zawierająca bardzo dużą liczbę urządzeń, klasy B dla sieci średnich, a klasy C dla sieci najmniejszych. Natomiast adresy klasy D przewidziane są do rozsyłania grupowego (ang. multicast), czyli do wysyłania datagramów do wielu urządzeń jednocześnie. Datagramy takie będą odebrane przez wszystkie urządzenia o adresie klasy D wskazanym w polu adresu odbiorcy.
Podsieci IP
Zarys idei
Wobec intensywnej rozbudowy sieci omówione powyżej adresowanie IP z podziałem na adres sieci i adres urządzenia okazało się mało praktyczne. W związku z tym wprowadzono dodatkowy podział pola adresu urządzenia na tzw. adres podsieci i adres urządzenia w podsieci. Dzięki temu adresy mogą odzwierciedlać podział sieci w obrębie danej organizacji, określanej przez adres sieci, na mniejsze sieci, określane przez adresy podsieci.
Podział na podsieci jest niewidoczny z zewnątrz danej sieci. Użytkownicy spoza sieci widzą całe pole adresu urządzenia wewnątrz sieci, natomiast nie rozróżniają adresu podsieci od adresu urządzenia w niej.
Maska podsieci
Sposób podziału adresu w obrębie sieci na adres podsieci i adres urządzenia może być wybrany dowolnie. Dla określenia które bity należą do której części wprowadzono tzw. maski podsieci. Są to 32-bitowe ciągi, w których każdy bit odpowiada odpowiedniemu bitowi adresu IP. Bit maski podsieci równy 1 oznacza, że bit na tej samej pozycji w adresie IP należy do adresu podsieci; 0 oznacza, że należy do adresu urządzenia w obrębie podsieci. Na pozycjach, które odpowiadają adresowi sieci, w masce podsieci pojawia się wartość 1. Zalecane jest stosowanie takiego podziału, w którym wszystkie bity adresu podsieci tworzą nieprzerwany ciąg, a po nim następuje adres urządzenia.
Maski podsieci zapisuje się zazwyczaj w postaci czterech liczb rozdzielonych kropkami, podobnie jak adresy IP. Mając dany adres IP oraz maskę podsieci, można wyznaczyć adres podsieci i adres urządzenia, stosując operację logiczną koniunkcji na bitach. Ilustruje to poniższy przykład:
Adres IP: 146.45.39.157, binarnie 10010010 00101101 00100111 10011101
Maska podsieci: 255.255.240.0, binarnie 11111111 11111111 11110000 00000000
Adres należy do klasy B, więc adresem sieci jest pierwsze 16 bitów:
146.45.0.0 10010010 00101101 00000000 00000000
Adres podsieci: 0.0.32.0 00000000 00000000 00100000 00000000
Adres urządzenia 7.157 00000000 00000000 00000111 10011101
Adresowanie ze stałą i zmienną maską podsieci
Najprostszym sposobem podziału sieci na podsieci jest przydzielenie tej samej długości pola adresu podsieci do każdej z podsieci i tym samym jednej maski podsieci dla całej sieci. Takie rozwiązanie umożliwia zastosowanie prostych algorytmów w routerach, natomiast może prowadzić do nieefektywnego wykorzystania puli adresów dostępnych w sieci. Problem pojawia się, gdy występują duże różnice pomiędzy wielkościami podsieci. Wówczas pole adresu urządzenia musi być na tyle długie, żeby zmieścić adresy wszystkich urządzeń w największej podsieci. Wskutek tego w innej, mniej licznej podsieci wiele adresów urządzeń pozostanie niewykorzystanych.
Aby umożliwić lepsze wykorzystanie dostępnego zakresu adresów, wprowadzono adresowanie ze zmiennym podziałem na adres podsieci i adres urządzenia. W tym rozwiązaniu każdej podsieci przydzielona zostaje odrębna maska, niezależna od pozostałych. Długość adresu urządzenia jest ustalana stosownie do liczby urządzeń w podsieci. Ten sposób adresowania nie jest jednak obsługiwany przez urządzenia starszej generacji.
komentarze
czesc
skomentowano: 2010-10-18 08:22:13 przez: magiera
Copyright © 2008-2010 EPrace oraz autorzy prac.